Go语言的一些练习题(二)
题目1
随机生成10个整数(1_100的范围)保存到数组,并倒序打印以及求平均值、求最大值和最大值的下标、并查找里面是否有55
思路:
- 使用rand
- 使用冒泡排序,倒序
- 求平均值、最大值为第一个、第一个的下标就是最大值的下标
- 使用二分法查找55
自己写的代码:
1 | |
代码优化:
- 修改 BinarySearch 函数,使其返回找到的目标值下标(若找到),而不是递归调用。移除了不必要的参数 leftIndex 和 rightIndex,并在函数内部初始化。
- 在 main() 函数中,调用 BinarySearch 函数查找55,并根据返回值决定是否输出找到的下标。将原来的递归调用替换为直接使用返回值。
1 | |
题目2
已知有个排序好(升序)的数组,要求插入一个元素,最后打印该数组,顺序依然是升序
思路:
- 先输出升序的数组
- 将数组变为切片
- 然后再随机插入一个数字,进行升序
自己写的代码:
1 | |
潜在问题和风险
- 代码安全性:在arrayToSlice函数中,你对原始数组进行了操作,并返回了一个新的切片。这里没有直接的问题,但是值得注意的是,如果对切片进行了修改,而原始数组没有被预期地更新,这可能会导致一些不容易发现的bug。需要确保在文档中明确这种行为,或者考虑使用不可变对象。
- 边界条件:在ascendingArray函数中,你使用了嵌套的for循环进行冒泡排序,但是没有对数组为空或者只有一个元素的情况进行特殊处理。尽管在这种情况下代码仍然有效,但是添加对这些边界条件的检查可以让代码更加健壮。
- 异常处理:Go语言中处理错误的方式与许多其他语言不同,需要显式地进行错误检查。虽然在这段代码中没有显式的错误处理需求,但在涉及到随机数生成、排序等可能失败的操作时,应考虑如何优雅地处理潜在的异常情况。
优化方向
- 性能效率:
- 在ascendingArray函数中,冒泡排序的效率在大型数据集上可能较差。考虑对于较大数组使用更高效的排序算法,如快速排序、归并排序等。
- 当arrayToSlice函数中的数组已知大小为10时,可以预先为切片分配足够的空间,这样append操作将更加高效。即使用slice = make([]int, 0, len(*arr)+1)初始化切片。
- 可维护性:
- 考虑将随机数生成的功能抽象到一个独立的函数中,这样可以提高代码的可读性和可维护性。你已经做到了这一点,这是一个好习惯。
- 函数命名应清晰表达其功能。例如,ascendingArray实际上是在对数组进行排序,而不是创建一个升序数组。建议更改为sortArrayAscending或其他更能准确描述功能的名称。
- 注释非常重要,但应确保其准确且有用。例如,在ascendingArray函数中,你对交换过程进行了注释,这是好的。不过,对整个函数的功能和算法的简短说明也会很有帮助。
- 代码整洁:
- 在main函数中,你初始化了一个[10]int类型的数组并填充了随机数,然后将其传递给不同的函数进行操作。这个过程很清晰,但是将初始化和填充数组的代码封装到一个独立的函数中,可以提高代码的可读性和重用性。
1 | |
题目3
定义一个3行4列的二维数组,逐个从键盘输入值,编写程序将四周的数据清0
原始的代码
1 | |
潜在问题
- 异常处理:当前代码缺乏对用户输入的异常处理。例如,如果用户输入的不是数字,fmt.Scan()将会失败,但程序不会对此做出任何反应或处理。考虑增加错误处理逻辑,确保程序的健壮性。
- 输入校验:程序没有校验用户输入的数字是否在合理的范围内。对于本例来说,虽然范围没有明确限制,但如果程序逻辑更复杂,可能需要考虑输入值的合法性(例如,是否为负数等)。
- 边界条件处理:在清除数组四周元素的逻辑中,直接将元素赋值为0。这种方式在处理具有特定边界条件要求的数据时可能会不够安全,尤其是在其他上下文中使用该数组时。
优化方向
- 代码重构:清除数组四周元素的逻辑略显冗余,可以考虑封装成一个单独的函数以提高代码的可读性和可维护性。例如,可以创建一个函数来处理特定行列的清零操作。
- 性能考虑:虽然对于一个3x4的数组来说性能不是问题,但如果处理更大的数组,可以考虑优化数据结构或算法,以减少不必要的操作,比如在清除四周元素时,避免对已清零的元素重复操作。
- 输入方式优化:当前通过嵌套循环和多次调用fmt.Scan()来读取输入,这种方式虽然简单但不够高效。考虑使用bufio.Scanner等工具来改善输入效率和用户体验。
- 增强交互性:对于需要从用户处获取输入的程序,考虑增加更友好的交互元素,比如输入提示、输入验证消息等,以提升程序的易用性。
- 使用更现代的Go特性:Go语言在不断发展,新的语言特性可能会提供更简洁、高效的解决方案。比如使用fmt.Printf(“%d\t”, matrix[i][j])直接在displayMatrix函数中打印矩阵,减少中间变量的使用。
优化后的代码
1 | |
题目4
定义一个4行4列的二维数组,逐个从键盘输入值,然后将第1行和第4行的数据进行交换,将第2行和第3行的数据进行交换
提示:可以尝试使用地址交换
最初自己写的代码
1 | |
潜在问题和风险
- 输入校验不够严格:虽然代码对输入进行了是否为数字的判断,但并未校验输入的整数是否在合理的范围内(例如,负数或超出数组索引范围的值)。这可能会导致逻辑错误或运行时panic。
- 错误处理不够优雅:当输入格式错误或读取失败时,程序会直接通过fmt.Println输出错误信息并进行一些逻辑处理(如i–),这样的处理方式较为简单,不利于构建更加健壮和用户友好的程序。
- 边界条件处理存在潜在风险:在处理输入错误时通过i–来重试当前循环,这可能会导致死循环或逻辑错误,尤其是当输入一直错误时。
优化建议
- 增强输入校验:除了检查输入字符是否为数字外,还应该检查扫描后的整数是否在预期的范围内(例如,0到100,或者更具体的范围,根据实际需求确定)。
- 改进错误处理:考虑使用更结构化的错误处理方式,例如定义错误类型或使用错误返回值来通知上层调用者发生了什么错误,而不是直接在底层输出错误信息。
- *避免使用***i–**进行错误处理:当输入错误时,应该考虑更安全的处理方式,比如使用一个额外的循环来专门处理输入校验失败的情况,避免影响主逻辑的索引计数。
- 代码可读性优化:虽然代码逻辑清晰,但在一些地方加入注释(比如swapRows函数的工作原理)可以进一步提高代码的可读性。
- 性能考虑:虽然这段程序的性能瓶颈不明显,但在处理大量数据或更复杂的逻辑时,需要注意循环、函数调用等可能的性能开销,考虑是否有必要优化这些方面。
- 异常处理:scanner.Scan()可能因为多种原因失败,除了打印错误信息外,考虑是否有更恰当的异常处理或恢复策略,以确保程序的健壮性。
调整后的代码
1 | |
题目5
保存10以内的奇数到数组,并倒序打印
1 | |
题目6
试写出实现查找的核心代码,比如已知数组 arr[10]string; 里面保存了十个元素,现要查找”AA”在其中是否存在,打印提示,如果有多个”AA”,也要找到对应的下标。
思路:
这里二分查找无法使用,因为二分查找仅能查找数组中唯一元素
需要使用顺序查找
自己写的代码
1 | |
潜在问题
- 变量命名:变量命名应尽量清晰和具有描述性。例如,demo可以改为data或dataSource,以更明确其作为数据源的角色。time作为存储下标的切片,命名容易引起误解,建议改为indices或foundIndices等。
- 硬编码:数组长度和初始值被硬编码在程序中,这限制了代码的灵活性和可重用性。建议通过函数参数等方式增加代码的通用性。
- 异常处理和输入验证:程序中未对用户输入进行验证。例如,如果用户输入为空字符串,程序将打印出未找到元素的消息,这可能不是预期的行为。建议增加输入有效性检查。
- 性能效率:虽然顺序查找在小数据集上表现良好,但对于更大的数据集,其效率可能较低。如果数据集较大或查找操作频繁,可能需要考虑使用更高效的算法,如二分查找或使用哈希表等数据结构。
优化方向
- 代码结构:可以将查找逻辑封装成一个独立的函数,这样做不仅增加了代码的可读性,也便于单元测试和复用。
- 性能优化:如果数据集允许,考虑使用更高效的数据结构。例如,如果需要频繁地进行查找操作,可以将数据存储在map中,这样可以将查找时间复杂度降低到O(1)。
- 输入处理:使用bufio.Scanner等工具对用户输入进行更有效的处理,同时增加输入验证以提高程序的健壮性。
- 可维护性:通过添加注释和文档,解释函数的用途、参数和返回值等,可以大大提高代码的可读性和可维护性。
1 | |
效果如下:
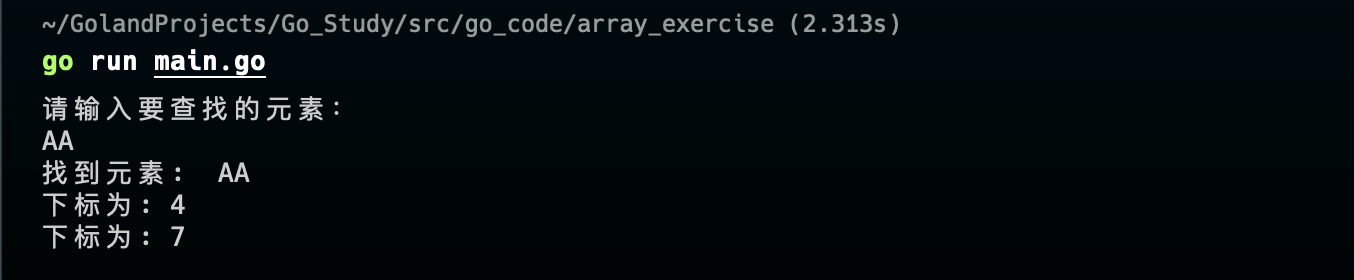
题目7
随机生成10个整数(1-100之间),使用冒泡排序法进行排序,然后使用二分查找法,查找是否有90这个数,并显示下标,如果没有则提示“找不到该数”
这题直接在第一题的基础上调整即可
1 | |
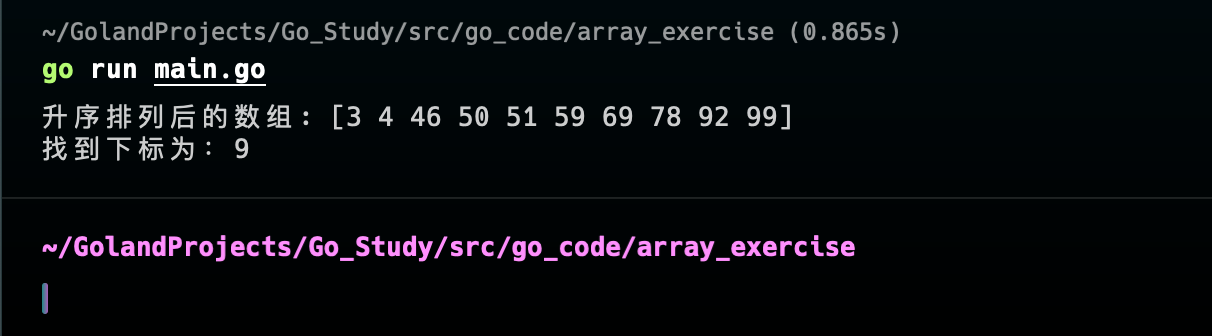
题目8
编写一个函数,可以接收一个数组,该数组有10个数,请找出最大的数和最小的数和对应的数组下标是多少?
自己写的代码
1 | |
潜在优化建议:
- 合并查找最大值和最小值的函数:虽然当前实现将查找最大值和最小值的逻辑分离为两个函数,但考虑到两者代码结构相似且处理的是同一数组,可以考虑合并为一个函数以减少重复代码。这样不仅提高了代码复用性,也简化了函数调用。
- 错误处理:在 findMaxAndIndex 和 findMinAndIndex 函数中,您对空数组进行了检查并抛出 panic。然而,由于本例中数组长度固定为10(在 main 函数中初始化),因此实际上不会出现空数组的情况。若考虑代码的通用性,可以保留此错误处理;否则,可以移除以简化代码。
1 | |
题目9
定义一个数组,并给出8个整数,求该数组中大于平均值的数的个数,和小于平均值的数的个数。
自己写的代码
1 | |
优化建议:
- 使用常量替代硬编码的数组长度: 已在代码中实现,定义了常量 arrayLength 表示数组长度。
- 输出大于和小于平均值的具体元素值: 已在 compare() 函数中实现,通过分别创建切片 greaterValues 和 lowerValues 存储对应元素值,并在循环中添加元素。最后,使用 fmt.Printf() 输出具体元素值及其个数。
- 对数组进行排序以方便输出有序元素值: 在 compare() 函数开始处,使用 sort.Ints() 对数组进行升序排序。这样,遍历数组时可以同时输出有序的大于和小于平均值的元素值。
优化后的代码
1 | |
题目10
跳水比赛,8个评委打分。运动员的成绩是8个成绩取掉一个最高分,去掉一个最低分,剩下的6个分数的平均分就是最后得分。使用一维数组实现如下功能:
(1)请把打最高分的评委和最低分的评委找出来。
(2)找出最佳评委和最差评委。最佳评委就是打分和最后得分最接近的评委。最差评委就是打分和最后得分相差最大的。如果最差和最佳存在多个,都需要打印出来。
思路
- 在键盘输入打分,最高分为10分,然后输入全部分数
- 使用函数找出最小和最大的元素,删掉,并算出平均分为最终得分
- 然后再通过每个元素与最终得分比较,差值最小的数的下标为最佳评委,最大的下标为最差评委
自己写的代码
1 | |
输出结果
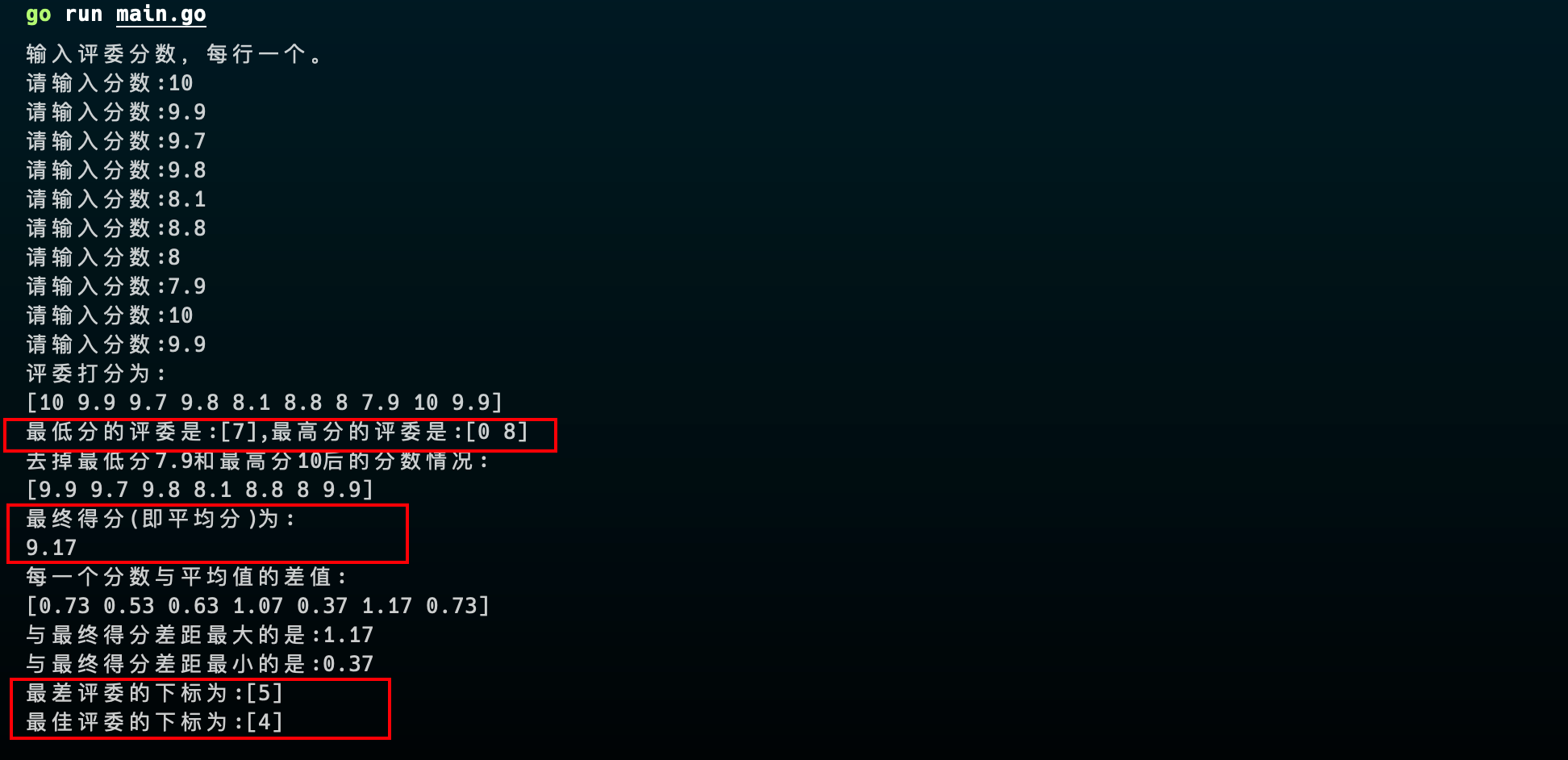
优化建议:
- 模块化:将主要功能分解为独立的函数,使代码结构更清晰。现有的Average函数可以进一步拆分为findMinMax和calculateAverage两个函数。
- 命名规范:遵循更具描述性的命名规则,如将FindMinMaxIndex改为findMinMaxScoresAndIndices,以明确该函数不仅返回最小值和最大值,还返回对应的评委索引。
- 错误处理:在main函数中对findMinMaxScoresAndIndices和findIndices函数的返回值进行错误检查,确保程序在遇到问题时能优雅地处理错误。
- 避免重复计算:在findIndices函数中,不需要再次调用FindMinMaxIndex,因为Average函数已经计算了平均分和去掉最高、最低分后的分数数组。可以直接使用这些结果。
- 简化findIndices函数:该函数可以简化为遍历新的分数数组,直接计算每个分数与平均分的差值,记录并输出最大差值和最小差值对应的评委索引。
- 修正fmt.Printf格式:修复fmt.Printf语句中的一些格式问题,如arr应使用%v而非%.2f来打印整型数组。
优化后的代码
1 | |
效果
